Regitrations
“Ownership” tell SPADE whether it has the right to delete the data file after it has been placed in the cache. For inbound transfers this is always true and so the <owner> element is ignored in this case (and should not appear in the registration by JAXB - the Java XML parser - reads unknown elements and puts them into their own list.) When picking up local files, if these are already in the warehouse then you don’t want them to be deleted so in local (= outbound?) registrations this can be set to “false” to avoid the warehouse copy from being deleted.
The <analyze> element should be set to “true” if you want a file associated with this registration to be passed for execution by the analysis task. My understanding is the this is where you would update the Dirac catalog, so you most likely want that set to “true” is you set up the appropriate script.
From Simon Patton
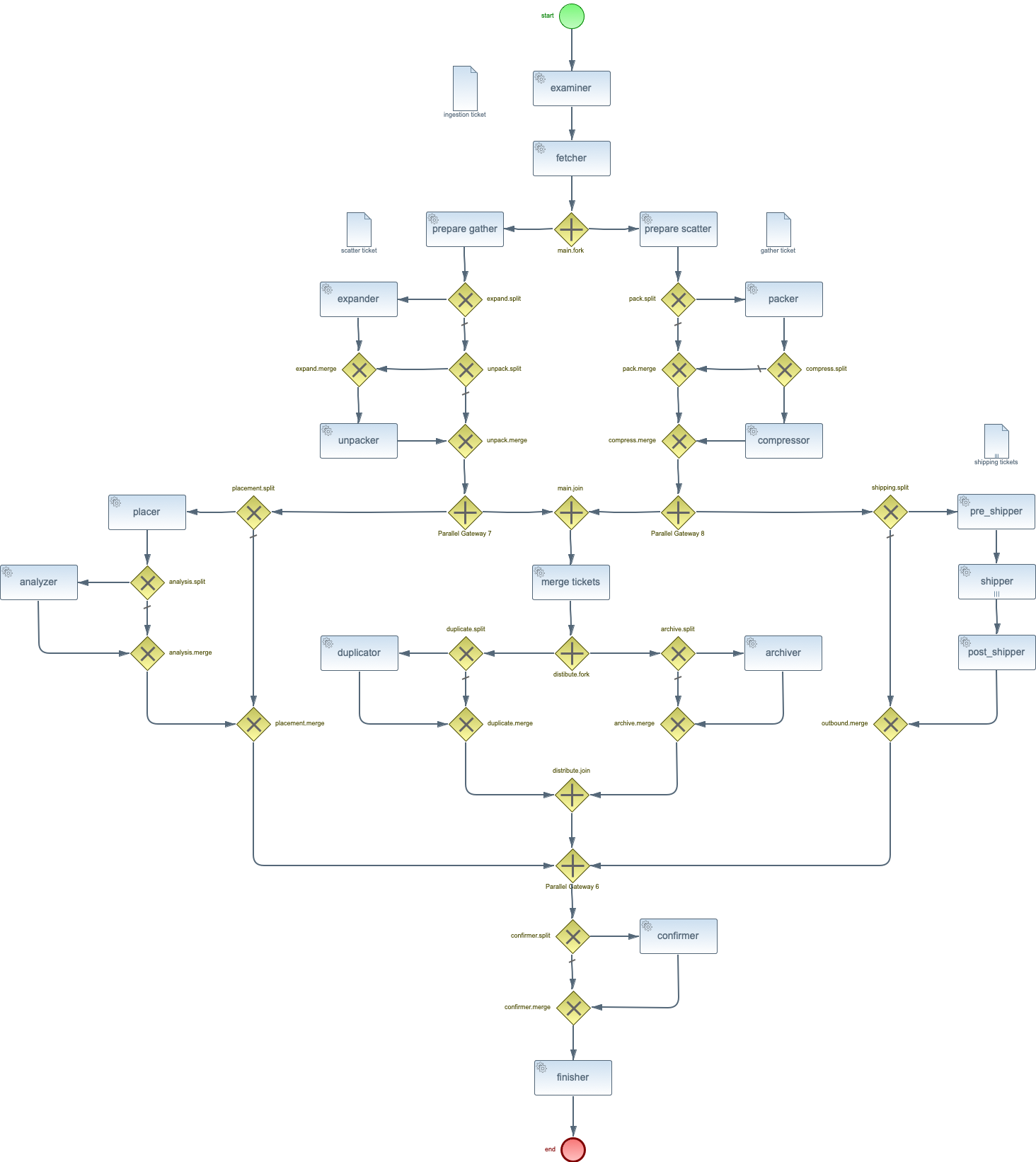
At the bottom is attached the BPMN (http://www.bpmn.org/) workflow diagram for SPADE. Each of the activities above is used to configure and task within that workflow. As to whether you need them or not, that depends on whether you need to change any of the defaults. In most instances, an activity appears in the spade.xml file in order to change the number of threads An example is the number `shipper` task are allocated for a SPADE that is shipping data. At NERSC we allocate 16 `shipper`. More than that and the transfer times per file appear to drop implying contention for resources on the SPADE node.)
As for what the task do, here is a summary of the ones listed above.
- Examiner : examines semaphore file and, along with registration, determines how the file will be handled.
- Fetcher : moves or copies the file or files into the cache.
- Placer : uses the PlacementPolicy sub-class to determine the destination of the data, packed, and/or compressed files (see below) and places them as appropriate.
- Pre-Shipped : prepares the file for transfer by however many shipper instance are required.
- Shipper : (_Note_ this marked as a "Multi-Instance" task which means that as many instances as are necessary are run each time the workflow runs, in this case we have on `shipper` for each `outbound-transfer` in the data’s registration.) Ships the data to an end point as defined by a `outbound-transfer`.
- Post-Shipped : determines whether all transfers succeeded or if one or more need to be re-scheduled.
- Finished : deletes all of the working files within the cache.
- Packer : packs the data file or data files, plus their metadata, into a single file (we’ve done `tar` and `h5` files so far)
- Compressor : compresses the packed data file to improve shipping times and minimize total bytes transferred.
- Expander : expands a compressed file to recover the packed file.
- Unpacker : unpacks a packed file to recover the original data files. (The recovered metadata file is only there for legacy purposes as the metadata file used by SPADE is transferred separately so it can be accessed without expansion and unpacking.)
- Analyzer : analyzes either the data, packed, or compressed file.
- Duplicator : duplicates the data file to a local disk that is not managed by SPADE.